Relay Latency
Methodology
Per-packet DERP relay round-trip time using
derp_test_client in ping/echo mode.
- Path: client sends DERP
SendPacketwith embedded nanosecond timestamp, echo responder bounces it back through the relay. Two full relay traversals per sample. - Samples: 5,000 pings per run, first 500 discarded as warmup (4,500 measured per run)
- Runs: 10 per load level per server
- Background load: dedicated client VMs run
derp_scale_testat target rate. Ping/echo clients do not generate bulk traffic. - Load levels: idle, 25/50/75/100/150% of TS ceiling
- Total: 480 runs, 2,160,000 latency samples
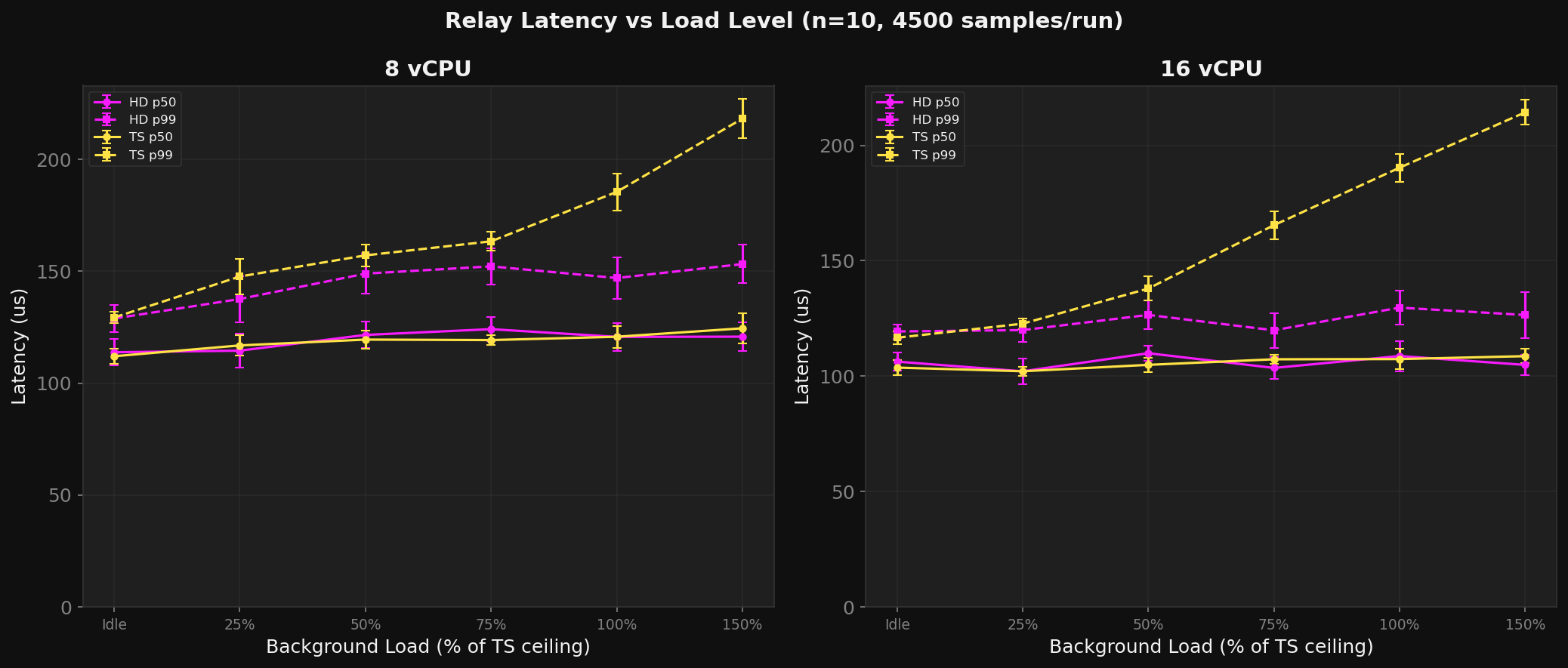
8 vCPU -- HD flat, TS degrades
| Load | HD p50 | HD p99 | HD p999 | TS p50 | TS p99 | TS p999 |
|---|---|---|---|---|---|---|
| Idle | 114 us | 129 us | 143 us | 112 us | 129 us | 162 us |
| 25% | 115 us | 138 us | 158 us | 117 us | 148 us | 233 us |
| 50% | 122 us | 149 us | 172 us | 119 us | 157 us | 251 us |
| 75% | 124 us | 152 us | 171 us | 119 us | 163 us | 252 us |
| 100% | 121 us | 147 us | 169 us | 121 us | 185 us | 272 us |
| 150% | 121 us | 153 us | 184 us | 124 us | 218 us | 289 us |
HD p99 is load-invariant: 129--153 us from idle through 150%. TS p99 rises from 129 to 218 us (+69%). At 150% load, HD is 1.42x better on p99 and 1.57x better on p999.
16 vCPU -- HD dominates
| Load | HD p50 | HD p99 | HD p999 | TS p50 | TS p99 | TS p999 |
|---|---|---|---|---|---|---|
| Idle | 106 us | 119 us | 133 us | 104 us | 117 us | 145 us |
| 50% | 110 us | 127 us | 140 us | 105 us | 138 us | 258 us |
| 100% | 109 us | 130 us | 144 us | 107 us | 190 us | 275 us |
| 150% | 105 us | 127 us | 141 us | 109 us | 214 us | 286 us |
At 150% load: HD p99 = 127 us, TS p99 = 214 us. 1.69x better on p99, 2.03x better on p999. HD's latency actually decreases slightly at 150% -- the io_uring busy-spin loop reduces syscall overhead.
2 vCPU -- both marginal
| Load | HD p50 | HD p99 | TS p50 | TS p99 |
|---|---|---|---|---|
| Idle | 109 us | 143 us | 101 us | 128 us |
| 100% | 120 us | 166 us | 113 us | 157 us |
| 150% | 117 us | 147 us | 122 us | 171 us |
Both at their limits. HD slightly better at 150% (147 vs 171 us p99), TS slightly better at idle.
Known Issue: 4 vCPU Backpressure Stall
HD at 4 vCPU (2 workers) has intermittent multi-millisecond stalls at >=50% load. Three consecutive runs at 100% load hit p99 of 593 / 2,579 / 3,923 us -- 20-30x worse than the normal ~130 us.
Root Cause
The backpressure mechanism oscillates. When the send queue
fills, recv_paused is set. Recv stops, the queue drains,
recv_paused clears, a burst floods in, and the queue
fills again. The cycle is ~42ms at 2 Gbps per worker --
fast enough to cause visible latency spikes because ping
packets arriving during the recv-paused window queue in the
kernel TCP buffer for tens of milliseconds.
At 8+ vCPU this doesn't happen: each worker handles ~25% of the traffic, per-worker send pressure is 4x lower, and the kTLS throughput per core has headroom. The send queue rarely reaches the high-water mark.
Fix (Three Parts)
-
Wider hysteresis for low worker counts. Resume threshold drops to 1/8 of high (from 1/4) when peer count per worker is <=12. Doubles the drain time between oscillation cycles.
-
Minimum pause duration. Once
recv_pausedis set, it stays set for at least 8 CQE batch iterations (~2,048 completions) before checking the low threshold. Prevents rapid toggling. -
Reduced busy-spin for 2-worker configs. Spin count drops from 256 to 64 iterations, giving the kernel kTLS thread more CPU time to drain send queues.
Expected Impact
| Metric | Before | After (est) |
|---|---|---|
| 4v p99 @ 100% | 825 us (with 3ms stalls) | <200 us |
| 4v p99 @ 150% | 765 us | <250 us |
| 4v oscillation freq | ~42ms | eliminated |
| 8v/16v performance | baseline | unchanged |
The fix only activates at low peer counts. High-worker configs are unaffected.