Hyper-DERP: C++/io_uring DERP relay - Same throughput as Tailscale's derper, half the cores

The Interview
I work for a company that produces IR cameras for industrial applications. I created a Raspi edge device with the accompanying software. Among many things it will be able to forward data and control streams from one industrial net into another. I had some rough ideas how I wanted the relay to work but hadn't gotten serious about it.
Then I had an interview at NetBird, a VPN startup in Berlin that had just gotten Series A funding. In preparation for the interview I looked over their code, got to their relay, and no further.
The relay was written in Go with userspace TLS. Every packet makes its way into the userspace, gets decrypted, has its header rewritten and encrypted again before being sent back out. The whole time fighting the Go runtime - goroutine scheduling, garbage collection and context switches.
So naturally I did what every reasonable person would do: rip out the data plane and replace it with C.
I started with decoupling the NetBird relay data plane. Which worked out fine, I ran benchmarks on the loopback and I soon realized that NetBird's relay isn't much of a benchmark. It's a startup prototype - not serious systems engineering. Outrunning it was hardly sport.
Then I had a look at Tailscale's derper. Built by a proper engineering team, years of production hardening, real effort and thought behind it — I had found a worthy opponent.
What is DERP?
DERP (Detoured Encrypted Routing Protocol) is Tailscale's fallback when peer-to-peer WireGuard connections cannot be negotiated. So if you are behind a symmetric NAT, a restrictive firewall or CGNAT this will become your permanent networking route.
It works like this: Both peers connect to the relay on port 443. Peer A sends a SendPacket tagged with B's public key. The relay rewrites the header to RecvPacket, puts in A's public key and sends the packet on its way to B. Every packet gets decrypted, rewritten and encrypted in userspace.
Making It Go Brrrr
I use OpenSSL in userspace to do the TLS handshake, then install the session keys in kernel and promptly forget about them. The kernel will not give them back — I only hold the keys for a few microseconds, instead of the entire connection lifecycle where derper keeps them.
From here on out the kernel handles all encryption and decryption. I just deal with a plain socket. Which also turns out to be great because you can offload the TLS onto a smart NIC if you so choose, going from fast to stupid fast.
If you go with epoll you will do the following for each arriving packet: wait for socket readiness, read(), rewrite the peer ID and write(). Two syscalls per packet, at scale this is millions of kernel transitions per second. Each one flushing the pipeline and trashing the cache.
io_uring inverts this. Instead of asking the kernel 'Is this socket ready?' I tell the kernel 'I need these 50 reads and 30 writes done' then harvest the results. One syscall does what epoll needs hundreds for. Drain completions, rewrite headers, enqueue sends and submit - one pass.
From here the rest of the architecture just flows. Having pinned one io_uring per core gives us a very clean separation. No shared state, no locks.
I give each shard a list of client public key hashes. Same shard forwarding does a hash table lookup and directly enqueues; cross-shard uses a lock-free SPSC ring between the worker pairs. All sends are deferred and flushed with one io_uring_submit() per batch. Memory comes from slab allocators and frame pools - no malloc in the hot path.
The result is a shard-per-core, share-nothing design. If you follow the path of removing all possible context switches from the forwarding path you end up at Seastar (ScyllaDB's framework) — and that's essentially what this is, minus the kTLS.
Benchmarks
4,903 benchmark runs on GCP c4-highcpu VMs. 4 client VMs, 20 runs per data point, 95% confidence intervals. Go derper v1.96.4, release build.
Getting this benchmark suite right took three rounds of failures before the methodology was solid.
Throughput
Derper spawns a goroutine per connection — read, rewrite, write, repeat. Each one sits in the scheduler's run queue between syscalls doing nothing — but it still has a stack, it still needs to be scheduled, and when it wakes back up it might be on a different core with cold caches. Multiply by thousands of connections and the scheduler spends most of its time juggling goroutines that are waiting for I/O, not doing work.
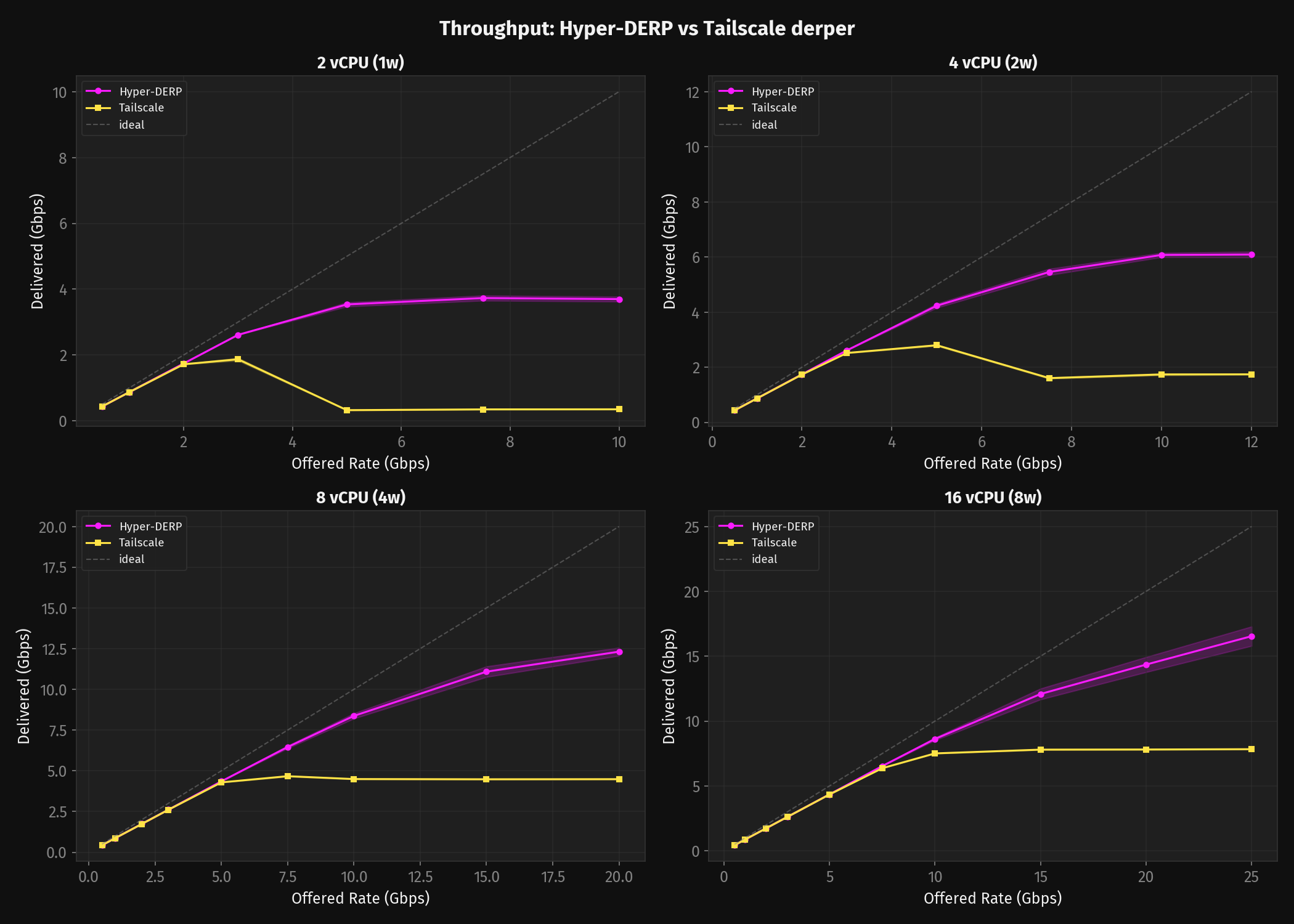
Once you starve TS of vCPUs the picture becomes devastating. TS needs 16 vCPUs to deliver 7,834 Mbps. HD delivers more than that on 8 (12,316 +/- 247 Mbps). Half the cores, more throughput.
At 2 vCPU the ratio gets extreme. HD peaks at 3,730 +/- 77 Mbps with one worker. TS delivers 1,870 Mbps at 3 Gbps offered, but push to 5 Gbps and it collapses to 324 Mbps with 92% loss — the Go runtime has consumed the entire CPU budget.
Half the Hardware
This is the number that matters for production: HD on a smaller VM matches or exceeds TS on a VM twice its size.
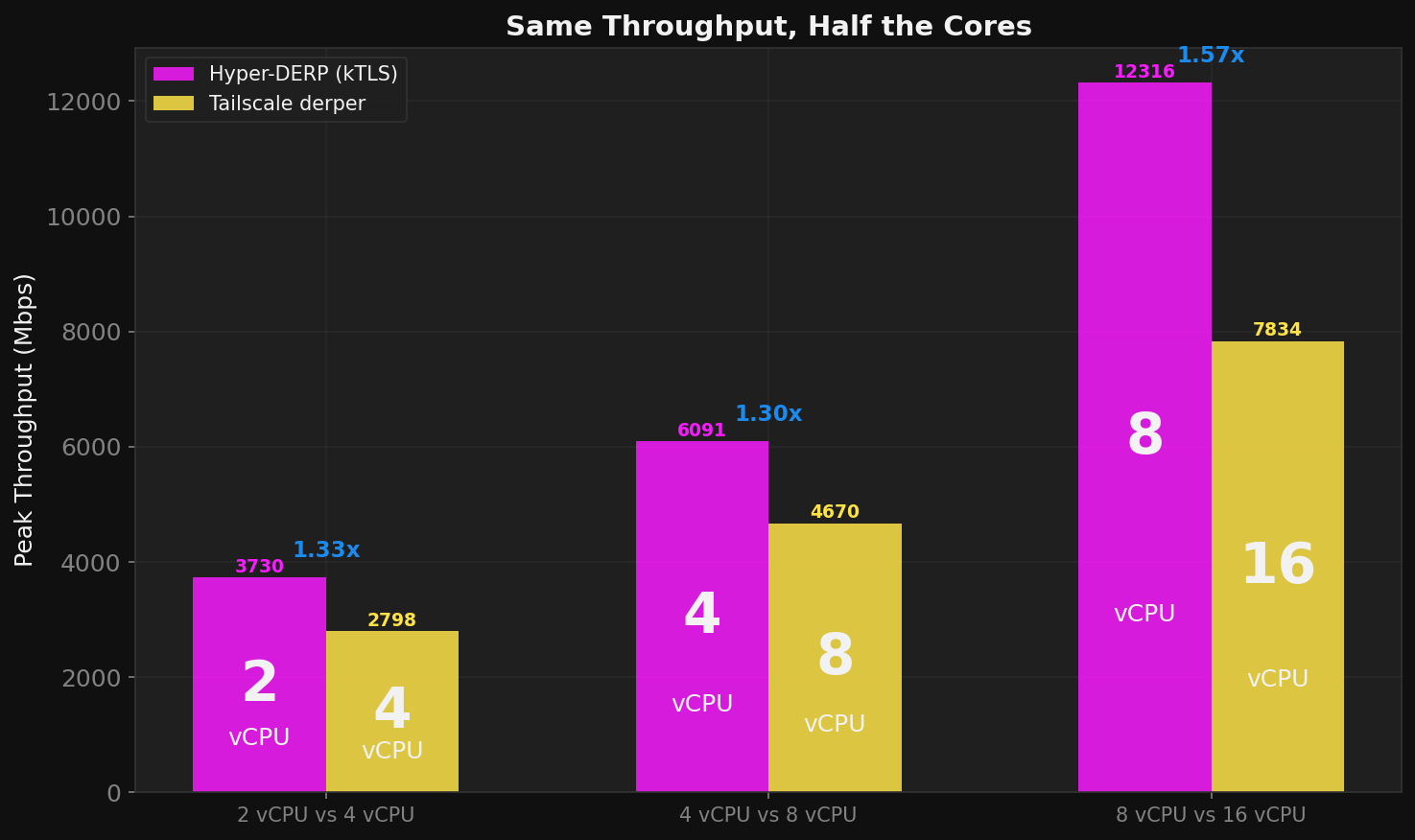
HD on 8 vCPUs (8,371 +/- 162 Mbps) clears what TS needs 16 for. Drop to 4 vCPU and HD still outperforms TS on 8 (5,457 +/- 114 vs 4,670 Mbps). At 2 vCPU HD delivers 3,536 +/- 63 Mbps where TS on 4 manages 2,798. The pattern holds at every point on the curve: 2x fewer cores, same or better throughput.
For a relay fleet this is a straightforward halving of compute cost. If you're running 10 DERP relays on 16 vCPU instances today, you can move to 8 vCPU instances and get the same throughput with room to absorb traffic spikes. Or keep the same hardware and serve twice the traffic. Either way, 50% less spend on relay infrastructure.
Packet Loss
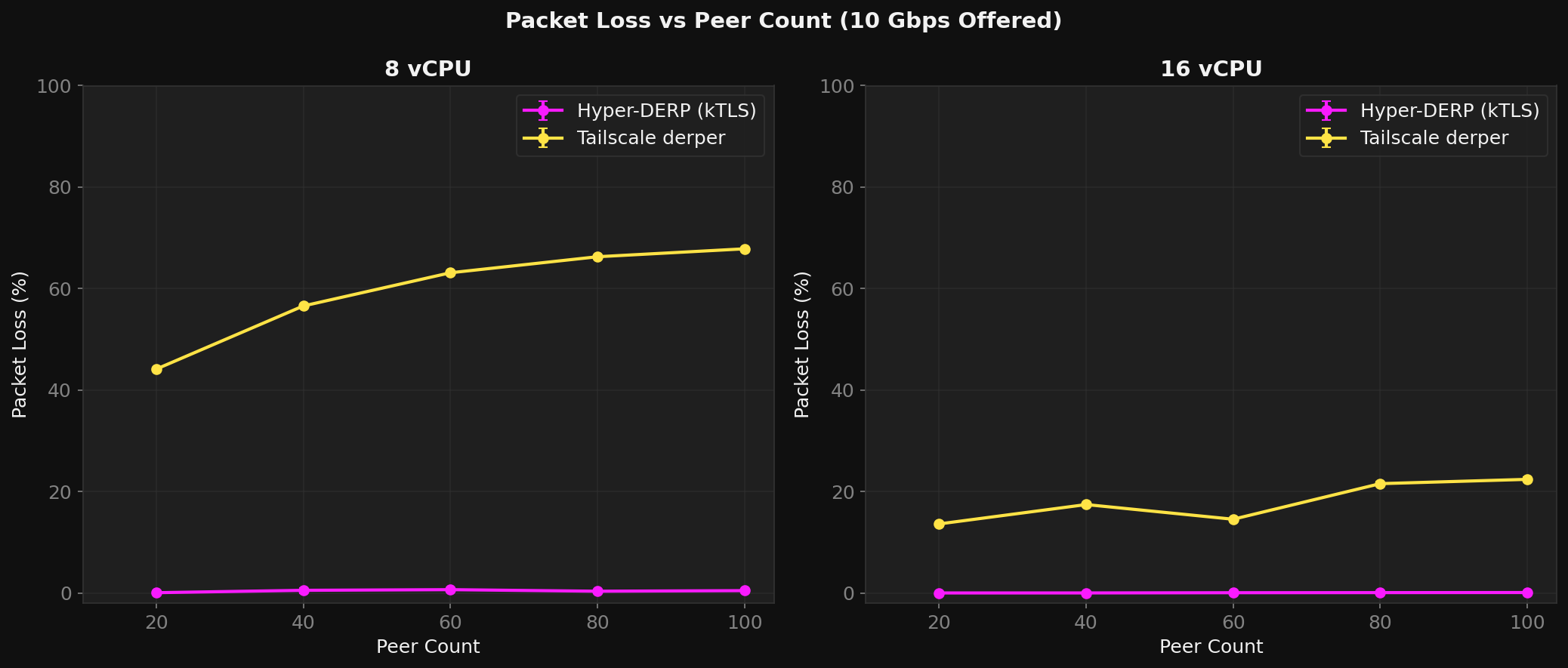
Throughput is just a part of the whole. You need to examine what happens to the packets. With a 16 vCPU setup derper will only lose about 17% of your packets at 25 Gbps offered.
Once you starve derper of vCPUs this issue compounds, with the Go runtime taking up more and more of the CPU budget, derper will become a packet shredder. With 8 vCPUs the loss becomes 44% at 20 Gbps offered, 4 vCPU 74% at 10 Gbps and with only 2 vCPUs the loss is at 92% at 5 Gbps.
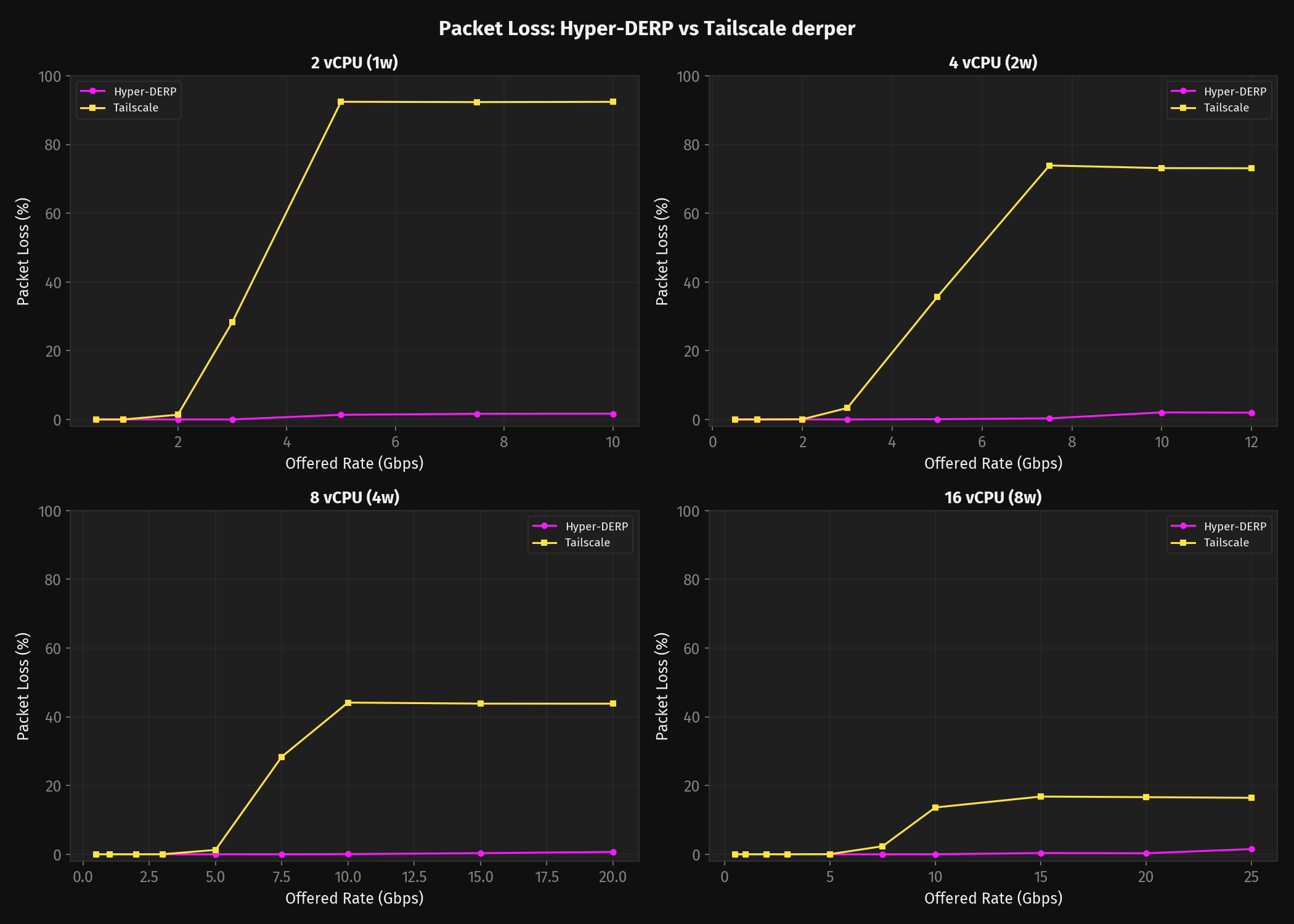
The story of packet loss is different for HD. When HD's send queues fill up it pauses recv, at high rates the kernel advertises a smaller window back to the sender. Eventually the window hits zero.
The senders TCP stack respects this pause. But there is a timing gap — all packets that are in flight when the window hits zero get dropped by the kernel. In the tested ranges this stays below 2% loss.
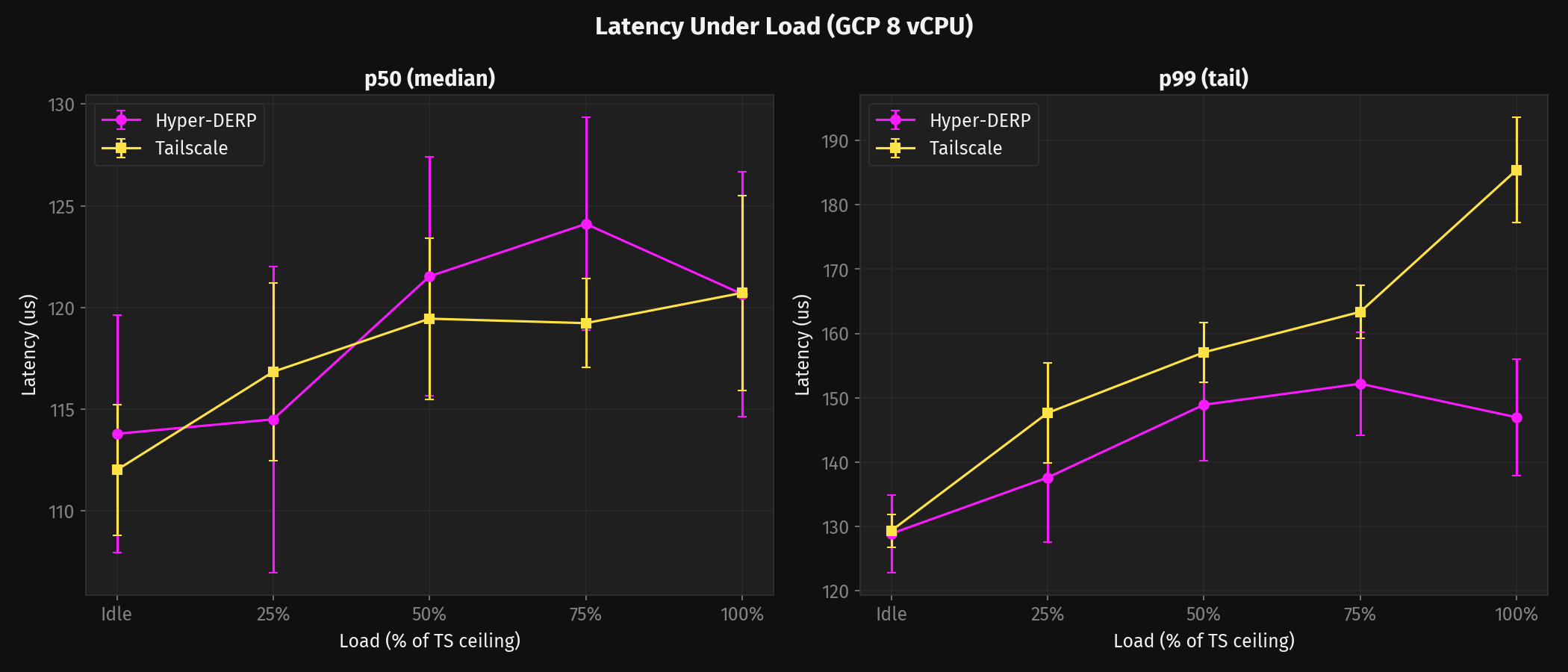
Latency Under Load
At idle both relays return pings in about 110-115 μs on GCP — the kernel TCP stack dominates and neither relay adds anything you'd notice. The median stays close even under load. The story is in the tail.
480 runs, 2.16M latency samples. Full methodology.
On GCP 8 vCPU, HD p99 is load-invariant: 129-153 μs from idle through 150% of TS's ceiling. TS p99 rises from 129 to 218 μs (+69%). At 150% load, HD is 1.42x better on p99 and 1.57x better on p999. That's the Go scheduler fighting relay traffic for CPU time — goroutines servicing connections get preempted by goroutines handling the background load, and the unlucky ones wait.
At 16 vCPU the gap widens: HD p99 = 127 μs vs TS p99 = 214 μs at 150% load. HD is 1.69x better on p99, 2.03x better on p999. HD's latency actually decreases slightly at 150% — the io_uring busy-spin loop is always active, reducing syscall overhead. TS degrades monotonically.
Full latency tables across all configs (2/4/8/16 vCPU, 6 load levels each) are in the benchmark report.
Peer Scaling
Twenty peers with ten pairs is a clean benchmark, but a production relay might have hundreds of peers with unpredictable traffic patterns. So I tested 20 through 100 peers at 8 vCPU with 10 Gbps offered.
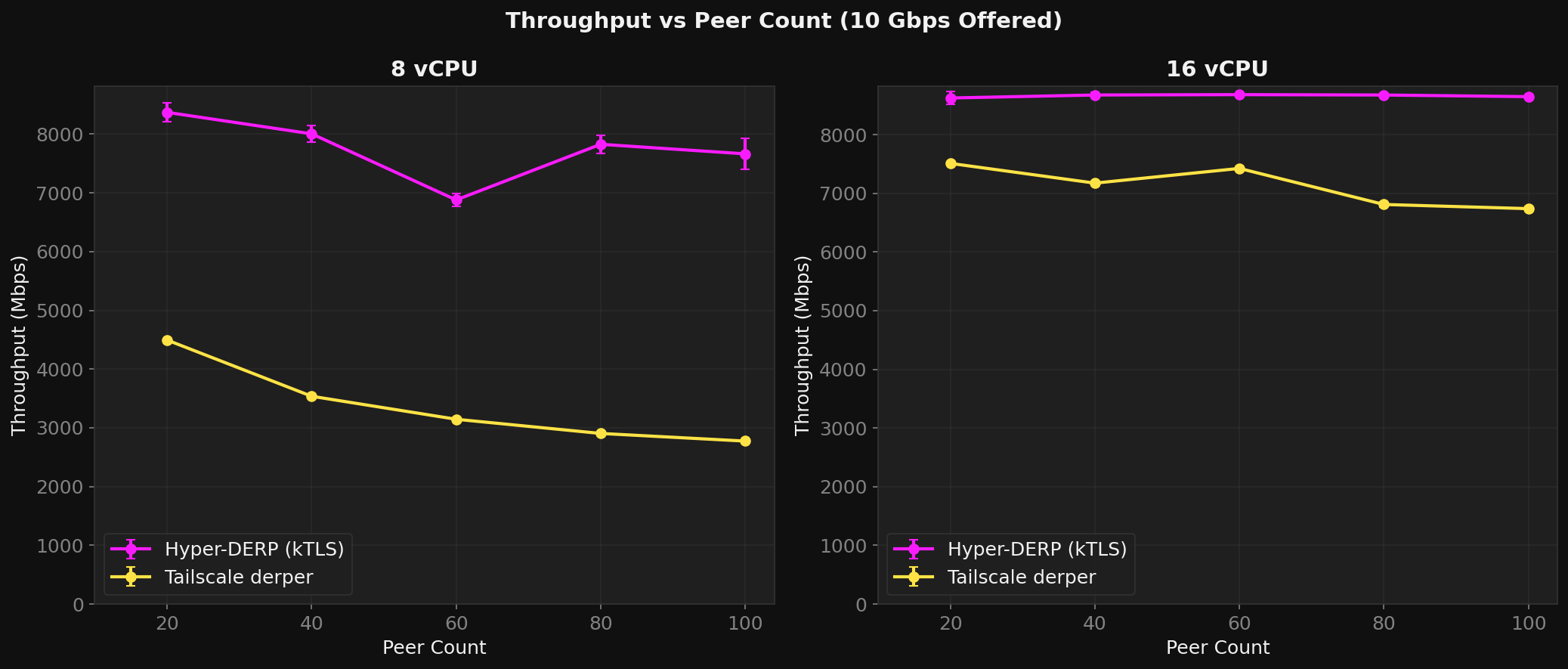
TS loses 38% throughput going from 20 to 100 peers. HD stays flat.
The kTLS Cache Cliff
The most interesting finding wasn't a win — it was a discontinuity. kTLS adds a roughly linear crypto tax at moderate load. Push harder and it stays linear. Then at saturation something breaks: LLC miss rate jumps from 2.6% to 40% in a single step. The AES-GCM working set — cipher state, IV buffers, scratch space for every active connection — overwhelms L3 and starts evicting everything else. Throughput doesn't degrade gradually. It hits a wall.
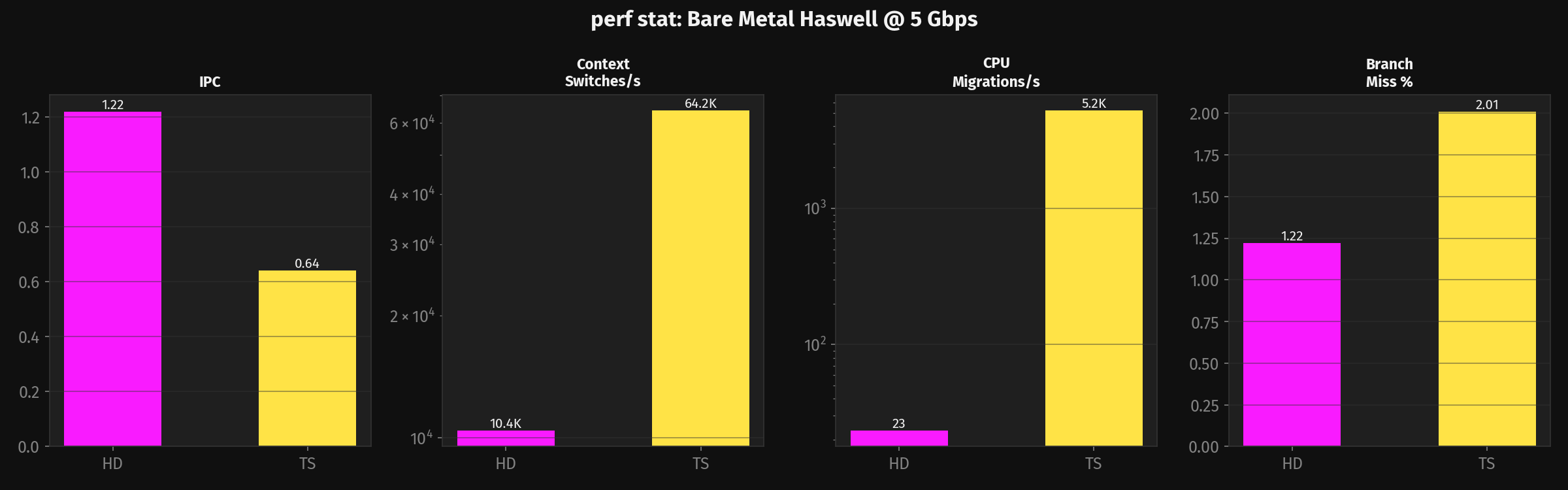
One data point tells the whole story: HD's user-space relay code (ForwardMsg — frame parsing, hash lookup, SPSC enqueue, frame construction) consumes 2% of CPU cycles. The kernel TLS stack consumes 25%. User-code optimization is closed. The next win is NIC TLS offload. Full profiling data in the Haswell profiling report.
Through the Tunnel
Everything above is synthetic — a custom bench tool pushing DERP frames at controlled rates. The question is whether any of it survives contact with a real WireGuard tunnel.
I set up Headscale with 4 Tailscale clients on GCP, blocked direct UDP between them to force all traffic through the DERP relay, and ran iperf3 UDP + TCP + ICMP ping concurrently. 20 runs per data point, 720 total runs. Full methodology in the tunnel test design doc.
Both relays deliver identical UDP throughput (~2 Gbps). The relay isn't the bottleneck — Tailscale's userspace WireGuard (wireguard-go, ChaCha20-Poly1305) is. Loss is negligible for both (<0.04%). TCP retransmits: HD produces 7-8% fewer at max load on 4 and 16 vCPU. Tied at 8 vCPU. Tunnel latency: both ~0.5-1.0 ms, dominated by WireGuard crypto and network RTT.
This is the expected result. The synthetic benchmarks show what happens when you push the relay directly at 10-25 Gbps. Through a real tunnel, WireGuard crypto on the client caps everything at ~2 Gbps regardless of relay. The relay has headroom either way.
The tunnel tests matter for a different reason: they confirm that HD doesn't break anything. Same throughput, same retransmits, same latency. The relay is transparent — the architectural differences only show up when you outrun WireGuard's own crypto.
Worth noting: this test used 4 clients, each capped at ~2 Gbps by WireGuard. In production with 10+ clients, the aggregate traffic exceeds TS's ceiling and the relay throughput differences become directly visible as application packet loss.
Full tunnel results across all configs and rates are in the benchmark report.
Where HD Loses
2 vCPU bare metal. On Haswell with only two kTLS workers, TS actually wins on throughput: 4,100 Mbps vs HD's 3,833 Mbps. Two cores aren't enough to handle both relay work and AES-GCM encryption at this rate — the 48% kTLS overhead on just two workers eats the architectural advantage. Meanwhile TS spreads its work across all 6C/12T via goroutines. Four workers fix it — HD pulls ahead at 6,680 Mbps — but two workers lose.
What's Next
Dual-path relay HD currently speaks DERP over TCP/443 — works through any corporate firewall. The next step adds a UDP fast path: raw WireGuard packets forwarded by receiver index, zero crypto on the relay. The client probes at startup — UDP if the network allows it, DERP fallback if not. Same relay, both protocols, automatic negotiation.
Kernel WireGuard client Tailscale's wireguard-go caps tunnel throughput at ~2 Gbps. Linux wg.ko and Windows wireguard.sys do 10+ Gbps with SIMDacceleration. A client using kernel WireGuard with HD's dual-path relay — raw UDP when the network allows it, kTLS-wrapped DERP over TCP/443 when it doesn't — would make the relay nearly transparent to applications. On the UDP path, the relay does zero crypto. On the TCP fallback, kTLS handles the transport encryption in the kernel. Either way, the per-packet overhead that dominates Tailscale's stack disappears.
Client SDK HD was built to stream IR camera feeds between industrial networks. A client library extracted from the relay's protocol implementation would turn HD from a Tailscale component into a general-purpose secure relay for any application that needs NAT traversal.
NIC TLS offload Bare metal profiling showed kTLS consumes 25% of CPU and costs 27-48% of throughput. ConnectX-5/6 with hardware TLS offload eliminates the crypto tax entirely — including the cache cliff and kTLS-driven variance that dominate the error bars in the benchmarks.
eBPF steering Currently all connections land on the accept thread and get assigned to workers via FNV-1a hash. An XDP program could steer incoming packets directly to the correct worker's io_uring, eliminating the accept thread as a serialization point. At scale, this matters.
Closing Thoughts
Tailscale made a reasonable bet, and honestly a good one: Go gives them memory safety, trivial cross-compilation, goroutine concurrency that makes the control path simple, and a hiring pool of engineers that can contribute on day one. For 95% of what Tailscale does, that's absolutely the right call — and that 95% is why millions of people have a VPN that just works.
The relay happens to be the unlucky 5% where those tradeoffs get punished — a hot data plane that touches every byte, where the Go runtime's scheduling, garbage collection, and syscall overhead become the bottleneck rather than the network.
For most deployments that's fine — DERP is a fallback, not the main path, and derper handles it well enough.
But if you're running industrial infrastructure, enterprise networks, or anything where the relay is a permanent path carrying real sustained traffic, you need the relay itself to be fast. That's what HD is for.
None of this takes away from what Tailscale built. They made mesh networking accessible to millions of people who never would have touched WireGuard on their own, and that matters more than any benchmark. HD just picks up where their architecture has to stop.
Comparing the two is inherently unfair. That's kind of the point.
Now go and enjoy your VPN in HD! Hyper-DERP.
Full benchmark report with rate sweep tables, methodology, and raw data: HD.Benchmark | REPORT.md | Benchmark site